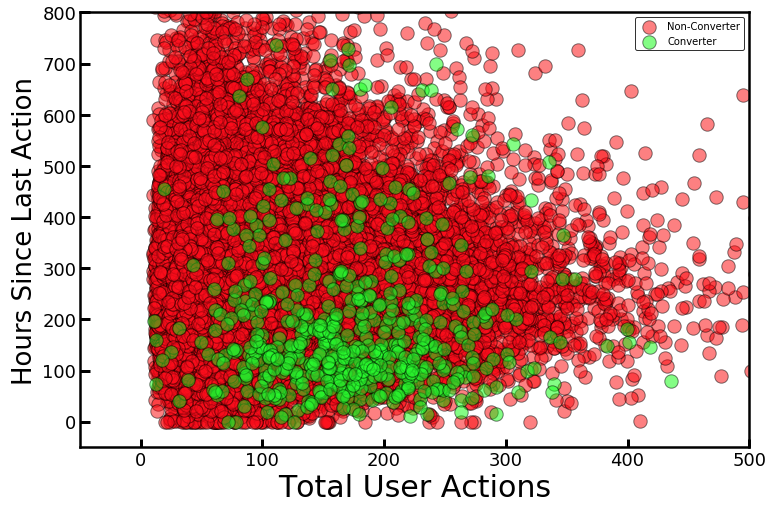
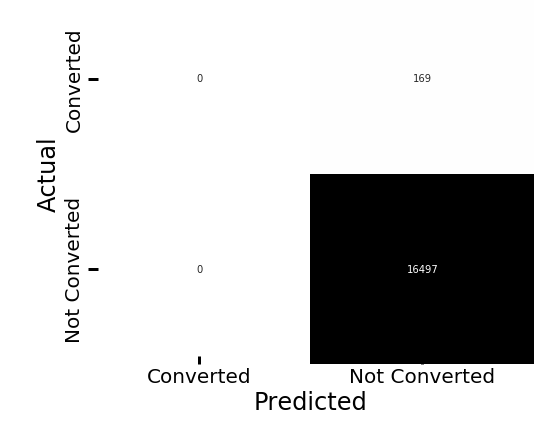
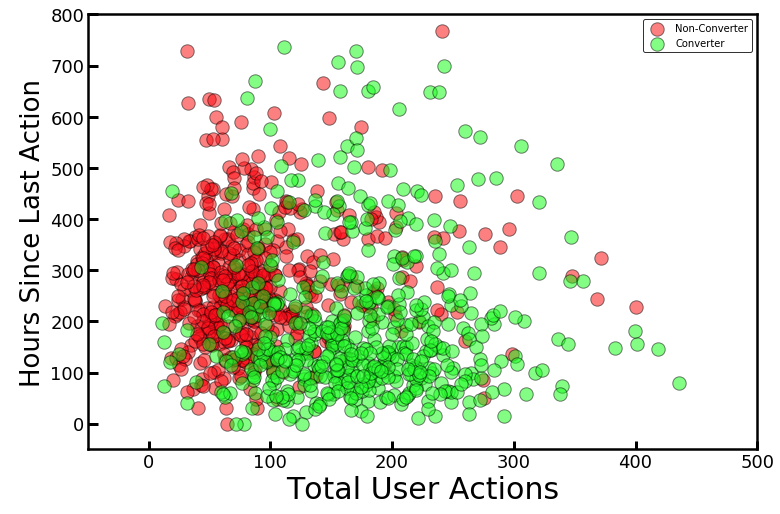
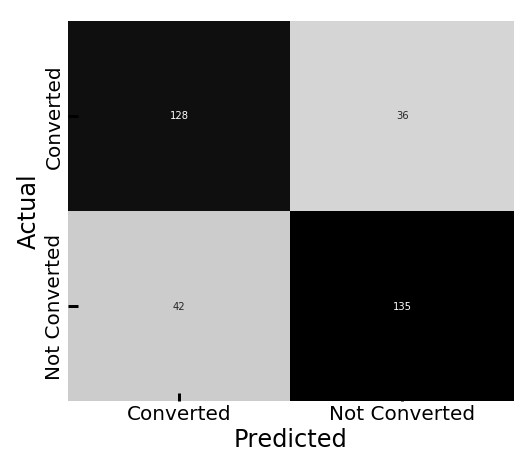
Weebly Engineering Blog
Blog
Blog